I’ve been spending a great deal of time as of late researching the background and roots of Cloud Computing in an effort to fully understand it. The goal behind this was to understand what Cloud computing is at all levels, and is quite a tall order. I think I have it figured out and am now looking for the community’s feedback to vet and fully mature my theory.
First a brief review of CAP Theorem, which states that all implemented systems can only sucessfully focus on two of the three capabilities (Consistency, Availability, and Partitioning tolerance). If you aren’t familiar with CAP Theory, please check out yesterday’s post and the resources at the bottom of that page.
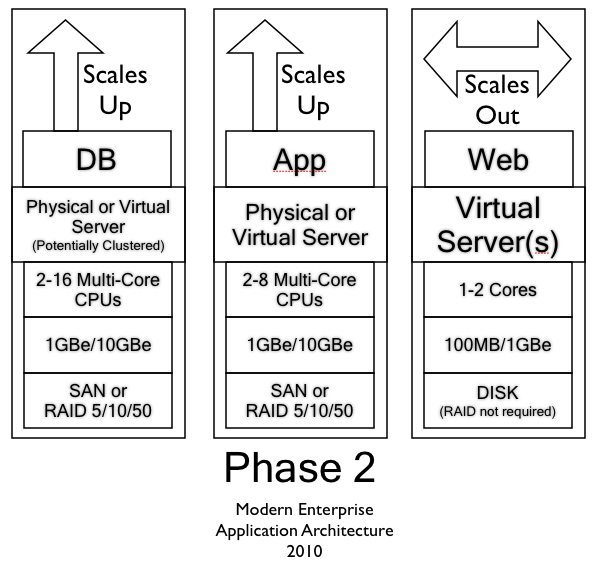
First some background – Below are the two phases deployed today in >90% of Enterprises. See “Where most Enterprise IT Architectures are today” for in-depth discussion on Phase 1 and Phase 2.

What follows is the theory:

Architecture Phase 3 – Cloud & The Real Time Web Explosion
The modern web has taken hold and Hyperscale applications have pushed a change in Architecture away from the monolithic-esque 3-Tier that traditional Enterprises still employ to that of a loosely coupled Services Oriented queued/grid like asynchronous design. This change became possible because developers and architects decided that a Rigidly Consistent and Highly Available system wasn’t necessarily required to hold all data used by their applications.
This was brought to the forefront by Amazon when it introduced its Dynamo paper in 2007 where Werner Vogels presented the fact that all of Amazon is not Rigidly Consistent but follows a mix of an Eventual Consistency model on some systems and a Rigidly Consistent model on others. Finally, the need for a system that operates at as close to 100% uptime and consistency, depending on a single system, was broken. Since then, we have found that all Hyperscale services follow this model: examples include Facebook, Twitter, Zynga, Amazon AWS, and Google.
Deeper into Phase 3
Why is Phase 3 so different than Phase 1 and 2?
Phase 3 Architecture not only stays up when systems fail, it assumes that systems can and will fail! In Hyperscale Architectures, only specific cases require RDBMS with Rigid Consistency, the rest of the time an Eventually Consistent model is fine. This move away from requiring systems to be up 100% of the time and maintaining Rigid Consistency (ACID compliance for all you DBAs) lowers not only the complexity of the applications and their architectures, but the cost of the hardware they are being implemented on.
Moore’s Law is pushing Phase 3
Until around 7 years ago, CPUs were constantly increasing in clock speed to keep up with Moore’s Law. Chip makers changed their strategy to keep up with Moore’s Law by changing from an increase in clock speed to increasing the numbers of cores operating at the same clock speed. There are only two ways to take advantage of this increase in cores approach, the first is to use Virtualization to slice up CPU cores and allocate either a small number of cores or even partial cores to an application. The second is to write software that is able to asynchronously use and take advantage of all of the cores available. Currently most enterprise software (Phase 2) is not capable of leveraging CPU resources in the second way described, however many systems in Phase 3 can.
How do IT processes fit into this?
Today most Enterprise IT shops have designed all of their processes, tools, scripts, etc. around supporting the applications and architectures mentioned in Phase 1 and Phase 2, NOT Phase 3. Phase 3 requires an entirely different set of processes, tools, etc. because it operates on an entirely different set of assumptions! How many Enterprise IT shops operate with assumptions such as:
Replicating Data 3 or more times in Real Time
Expecting that 2 or more servers (nodes) in a system can be down (this is acceptable)
Expecting that an entire Rack or Site can be down
(These are just a few examples)
Why will Enterprises be compelled to move to Phase 3 (eventually)?
The short answer is cost savings and operational efficiency, the longer answer is around the reduction in systems complexity. The more complex the hardware and software stack is (think of this as the number of moving parts) the higher the likelihood of a failure. Also, the more complicated the stack of hardware and software become, the more difficult it is to manage and maintain. This leads to lower efficiencies and higher costs, at the same time making the environment more brittle to changes (which is why we need ITILv3 in Enterprises today). To gain flexibility and elasticity you have to shed complex systems with hundreds of interdependencies and an operational assumption of all components being up as close to 100% as possible.
Conclusion:
Different systems have different requirements, most systems do not in fact need an ACID compliant consistency model (even thought today most have been developed around one. Some specific cases need ACID properties maintained and a level of 100% Consistency, but these are in the minority (whether in the Cloud or in the Enterprise). This is causing a split in data models between the current CA (Consistency and Availability – “Traditional Enterprise Applications) and AP (Availability and Partitioning tolerance – many Cloud Applications). A combination of these is the long term answer for the Enterprise and will be what IT must learn to support (both philosophically and operationally).
Follow me on Twitter if you want to discuss @mccrory
